本文共 4869 字,大约阅读时间需要 16 分钟。
logstash 的output和input的输入输出插件
之前的简答查询字符串格式 https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-simple-query-string-query.html GET /_search { “query”: {指明这是一个查询i请求 “simple_query_string” : {简单字符串查询 “query”: ““fried eggs” +(eggplant | potato) -frittata”, 并指明查询内容 “fields”: [“title^5”, “body”],指明在哪些字段查询, “default_operator”: “and” } } }
GET /_search { “query”: {指明这是一个查询i请求 “simple_query_string” : {简单字符串查询 “query”: ““fried eggs” +(eggplant | potato) -frittata”, 并指明查询内容 “fields”: [“title^5”, “body”],指明在哪些字段查询, “default_operator”: “and” } } } 在course找jianfa和zhang的人
 https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html
 需要加""引号
需要加""引号 logstash的确可以从很多位置输入数据,也可以输出数据,filter插件对数据正规化https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
logstash的确可以从很多位置输入数据,也可以输出数据,filter插件对数据正规化https://www.elastic.co/guide/en/logstash/current/filter-plugins.html 将大段数据生成一个json格式
将大段数据生成一个json格式 能将ip地址归类到所属的城市或国家,能判断这个ip地址访问来源的
能将ip地址归类到所属的城市或国家,能判断这个ip地址访问来源的 非常有用的过滤器插件,能够把给定的文本利用正则表达式来匹配出制定内容以后,给定义一个字段名称 %匹配到的内容:自定义的字段名称
https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html grok: %{SYNTAX:SEMANTIC} SYNTAX:预定义的模式名称; SEMANTIC:给模式匹配到的文本所定义的键名;
grok: %{SYNTAX:SEMANTIC} SYNTAX:预定义的模式名称; SEMANTIC:给模式匹配到的文本所定义的键名; 1.2.3.4 GET /logo.jpg 203 0.12 日志用下面格式匹配 %{IP:clientip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
第一个字段为clientip,匹配单词,word的模式,是grok内建专门匹配字符串的 { clientip: 1.2.3.4, method: GET, request: /logo.jpg, bytes: 203, duration: 0.12}
%{IPORHOST:client_ip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)" %{HOST:domain} %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent} "(%{WORD:x_forword}|-)" (%{URIHOST:upstream_host}|-) %{NUMBER:upstream_response} (%{WORD:upstream_cache_status}|-) %{QS:upstream_content_type} (%{BASE16FLOAT:upstream_response_time}) > (%{BASE16FLOAT:request_time}) "message" => "%{IPORHOST:clientip} \[%{HTTPDATE:time}\] \"%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:http_status_code} %{NUMBER:bytes} \"(? \S+)\" \"(? \S+)\" \"(? \S+)\"" filter { grok { match => { "message" => "%{IPORHOST:clientip} \[%{HTTPDATE:time}\] \"%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:http_status_code} %{NUMBER:bytes} \"(? \S+)\" \"(? \S+)\" \"(? \S+)\"" } remote_field: message } } nginx.remote.ip [nginx][remote][ip] grok有些内建的pattern


 内建模式不够用,可以自行定义,或者用grok直接定义使用的模式https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
内建模式不够用,可以自行定义,或者用grok直接定义使用的模式https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html 调用内建的已有格式信息 input { file { path => “/var/log/http.log” } } filter { grok { match => { “message” => “%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}” } } }
调用内建的已有格式信息 input { file { path => “/var/log/http.log” } } filter { grok { match => { “message” => “%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}” } } } 还要指明到哪去使用定义好的模式,来生成截取后的键值对
 表示源客户端真正ip地址是什么
表示源客户端真正ip地址是什么 有这些来截取内容 %{IPORHOST:client_ip} %{USER:ident} %{USER:auth} [%{HTTPDATE:timestamp}] “(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)” %{HOST:domain} %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent} “(%{WORD:x_forword}|-)” (%{URIHOST:upstream_host}|-) %{NUMBER:upstream_response} (%{WORD:upstream_cache_status}|-) %{QS:upstream_content_type} (%{BASE16FLOAT:upstream_response_time}) > (%{BASE16FLOAT:request_time})
有这些来截取内容 %{IPORHOST:client_ip} %{USER:ident} %{USER:auth} [%{HTTPDATE:timestamp}] “(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)” %{HOST:domain} %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent} “(%{WORD:x_forword}|-)” (%{URIHOST:upstream_host}|-) %{NUMBER:upstream_response} (%{WORD:upstream_cache_status}|-) %{QS:upstream_content_type} (%{BASE16FLOAT:upstream_response_time}) > (%{BASE16FLOAT:request_time}) 编辑配置文件

 -t做下语法测试不真正执行语法没事,但是截取和语法两回事,访问站点
-t做下语法测试不真正执行语法没事,但是截取和语法两回事,访问站点

 把filebeat删除
把filebeat删除 输出到ELS中https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html 一般索引和主机必须指明
输出到ELS中https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html 一般索引和主机必须指明
 指明index名称
指明index名称
 端口默认是9200
端口默认是9200 从beats收取日志。通过filter过滤,输出到ELS
从beats收取日志。通过filter过滤,输出到ELS **现在实现的场景是,有一个nginx服务器,上面装了一个filebeat,filebeat取得本机日志,发送给logstash
logstash有三个插件, input,从beats接收数据 filter 接到数据给filter插件,过滤正规化 output 正规化后发送给output插件, 再扔给ELS集群,ELS收到以后,放到索引中,建立成索引, 还有一个主机是kibana,kibana能够通过索引查询以后把结果展示给用户 ** 配置文件好了,做一下语法测试
配置文件好了,做一下语法测试 访问下服务
访问下服务 就有索引了
就有索引了 
 不加*号是匹配不到的
不加*号是匹配不到的

 message字段保留着,但是其他截取已经完成了 现在就可以做可视化了
message字段保留着,但是其他截取已经完成了 现在就可以做可视化了 splits分割
splits分割 也可根据响应码区分,来看哪个比较多
也可根据响应码区分,来看哪个比较多 请求的url
请求的url 可以保存下来
可以保存下来 响应码的也保存下来
响应码的也保存下来 可以在dashboard上导入这些图片
可以在dashboard上导入这些图片 **其他类似的日志信息用这种方式来导入导出了 **
**其他类似的日志信息用这种方式来导入导出了 ** 众多输出日志的主机和logstash之间加一层中间层,避免logstash压垮,这个是可以一个或多个redis中间服务器,日志都发给redis,由redis统一发给logstash’

 https://www.elastic.co/guide/en/beats/filebeat/5.5/redis-output.html filebeat可以发给redis,redis发给logstash
https://www.elastic.co/guide/en/beats/filebeat/5.5/redis-output.html filebeat可以发给redis,redis发给logstash 找一个主机扮演redis服务器
找一个主机扮演redis服务器
 定义绑定地址
定义绑定地址 认证密码修改
认证密码修改 使用filebeat把redis当做输出位置
使用filebeat把redis当做输出位置 把logstash的注释掉,在下面自己加一个配置段
把logstash的注释掉,在下面自己加一个配置段 https://www.elastic.co/guide/en/beats/filebeat/5.5/redis-output.htmloutput.redis: hosts: [“localhost”] password: “my_password” key: “filebeat” db: 0 默认redis数据库从0-15 timeout: 5
https://www.elastic.co/guide/en/beats/filebeat/5.5/redis-output.htmloutput.redis: hosts: [“localhost”] password: “my_password” key: “filebeat” db: 0 默认redis数据库从0-15 timeout: 5
 访问服务制造一些日志
访问服务制造一些日志 keys * 获取所有键 获取键的值 LINDEX获取指定键的值 LLEN长度
keys * 获取所有键 获取键的值 LINDEX获取指定键的值 LLEN长度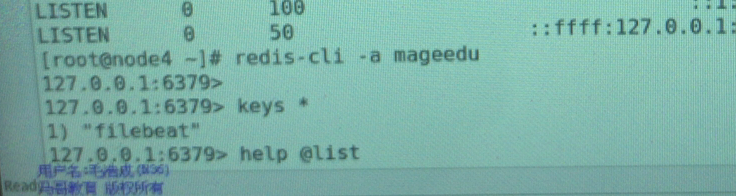
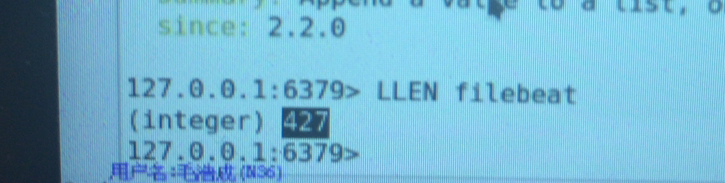 LPOP弹一个信息出来
LPOP弹一个信息出来 把这个400多的数据读出来,放到ELS 编辑logstash文件
把这个400多的数据读出来,放到ELS 编辑logstash文件 input改成redishttps://www.elastic.co/guide/en/logstash/current/plugins-inputs-redis.html
input改成redishttps://www.elastic.co/guide/en/logstash/current/plugins-inputs-redis.html
 测试语法并启动
测试语法并启动 现在就读取到数据了
现在就读取到数据了 这里能读出来说明发往ES也没有问题,就可以修改配置文件了
这里能读出来说明发往ES也没有问题,就可以修改配置文件了

 就获取到数据了
就获取到数据了 现在就能把数据送到redis,redis把数据送到logstash
现在就能把数据送到redis,redis把数据送到logstash 产生日志主机装filebeat,收取到日志发给redis,用logstash从redis取出数据导入到es集群,集群又多大,取决于你的数据量又多大
产生日志主机装filebeat,收取到日志发给redis,用logstash从redis取出数据导入到es集群,集群又多大,取决于你的数据量又多大 可以保存为图片查看关注的值
可以保存为图片查看关注的值 简单字符串的语法格式 http://lucene.apache.org/core/6_6_0/queryparser/org/apache/lucene/queryparser/classic/package-summary.html#package.description
简单字符串的语法格式 http://lucene.apache.org/core/6_6_0/queryparser/org/apache/lucene/queryparser/classic/package-summary.html#package.description 刚才搭建的有一个kibanaserver,又三台主机提供ES服务,kibana链接其中一个节点来显示数据,es数据源是前端的logstash(拿到数据清理导入到ES集群),数据源来自于redis,redis数据源来自众多主机,tomcat,nginx,apache redis做负载均衡没必要做集群 logstash一个不够用,就加两个 es的jvm堆内存会很大,构建索引本身非常消耗内存和cpu
转载地址:http://nckgn.baihongyu.com/